주어진 문제
- 요인분석.
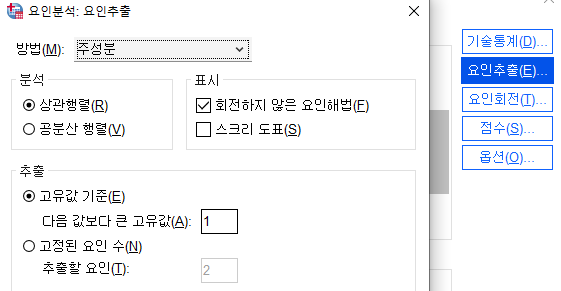
- 1) 친숙도 1~3 , 전반적 만족도 1~4까지의 변수로 요인분석
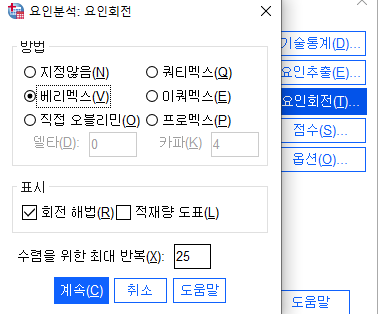
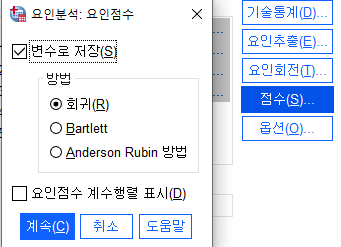
- (고유값 기준1 , 베리맥스법으로 회전 , 변수로 저장, 크기순 정렬 )
- 2) 재구매의도 1~3까지의 변수로 요인분석
- (고유값 기준1 , 베리맥스법으로 회전 , 변수로 저장, 크기순 정렬 )
- 3) 요인분석결과로 생긴 요인점수변수를 명칭을 바꾸어라.
- 1) 친숙도 1~3 , 전반적 만족도 1~4까지의 변수로 요인분석
- 신뢰도 분석
- 각 요인별 측정문항(변수)에 대한 신뢰도 분석을 하라.
- 마무리
- 표로 정리하고 두번의 요인분석결과 구성된 요인들에 설명과 신뢰도 분석 결과를 각각 해석을 하라.
요인분석
많은 변수들의 상호 관련성을 소수의 요인(factor)으로 추출하여 전체변수들의 공통요인을 찾아내 각 변수가 받는 영향의 정도와 그 집단의 특성을 규명하는 통계분석방법
요인분석은 분석-> 차원 축소 -> 요인분석에 위치한다

1. 일단 친숙도와 만족도 부터 요인분석을 진행 해보려고 한다

각 문제에 주어진 설정을 진행한다.
*KMO(Karser Meyer Olkin)는 변수들 간의 상관성을 나타내는 척도!
전체 상관관계 행렬이 요인분석에 적합한지를 나타내는 지표입니다.
KMO 0.6이상일 때 적합하고 이보다 낮으면 변수들 간의 상관성이 별로 없어서
요인분석의 변수들로써 적당하지 않습니다



0.764로써 적합하네요!
아래 사진을 보면 전체(노란색) eigen value로 고유치 값입니다!
누적%는 누적분산으로써 60%이상이 될때까지 요인을 나눕니다!
2개의 요인을 자동으로 생성하고 60%이상이므로 멈춘것같습니다

회전된 성분행렬을 보시면 성분1은 만족도 기준으로 나온것 같습니다
만족도요인에 적합할수록 1에가까워지는데 만족도4가 많은 기여를 하기에 큰값을 가지고 있음을 알수 있습니다.
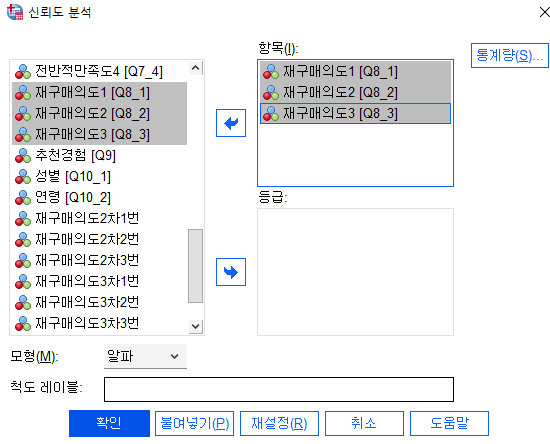
2) 재구매 의도도 동일하게 해줍니다!
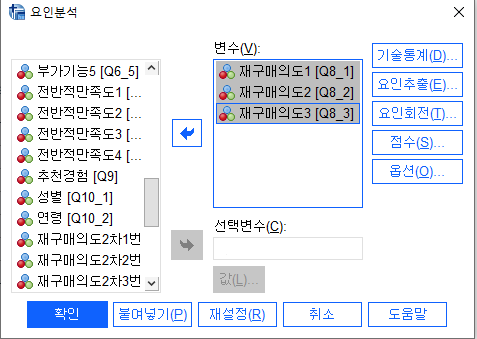
분명 재구매의도도 베리믹스법으로 회전을 시켜줬는데 회전한값이 나오지 않습니다
그이유는 회전할 이유가 없기때문인데요 요인이 1개뿐이라
할이유가 없다고 판단하여 안했다는 겁니다!

3)요인점수변수의 명칭을 변경하기
Fac1_1 FAC2_1 / FAC1_2
만족도 친숙도 재구매의도

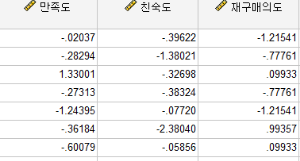
이렇게 한번씩 돌리면 요인점수변수가 나옵니다
FAC1_1(성분1_1번째)
FAC2_1(성분2_1번째)
FAC1_2(성분1_2번째)
이렇게 이해하시면 될 것같습니다!
신뢰도
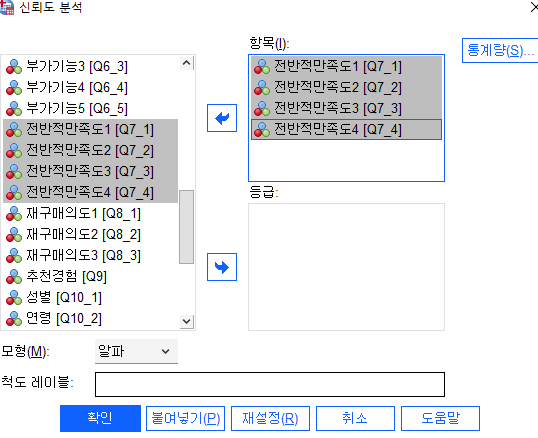
신뢰도 분석은 분석 -> 척도분석-> 신뢰도분석에 있습니다!

신뢰도 분석의 중요한점은 해당 요인별로 한번씩해야하는 점인데요
일단 친숙도부터 돌리도록하겠습니다.


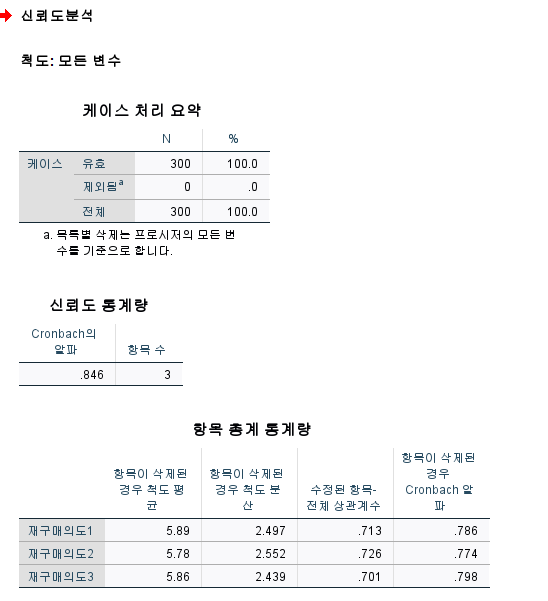
분석을하면 cronbach의 알파를본다 이것이 신뢰도이다!

나머지 요인들도 해준다

정리
표
| 요인명칭 | 변수명 | 요인적재값 (factor loading) |
고유치(값) | 누적분산(%) | 신뢰계수 (Cronbach's a) |
| 만족도 | 전반적만족도4 전반적만족도3 전반적만족도2 전반적만족도1 |
0.901 0.897 0.893 0.663 |
2.856 | 40.802 | 0.861 |
| 친숙도 | 스마트폰친숙도3 스마트폰친숙도2 스마트폰친숙도1 |
0.871 0.849 0.814 |
2.146 | 71.452 | 0.799 |
| KMO=0.764 Bartlett's X^2=951.034 p =0.000 | |||||
| 재구매의도 | 재구매의도2 재구매의도1 재구매의도3 |
0.882 0.875 0.867 |
2.296 | 76.526 | 0.846 |
| KMO=0.730 Bartlett's X^2=374.291 p =0.000 | |||||
결과해석
두 번의 요인분석결과에 대해 각각 구성된 요인에 대해 설명하시오.
첫번째요인분석은 7개의 항목으로 요인분석을 하였다
KMO측도는 0.764 나타났고 누적분산이 71.452로 나타나 구성된 2개의 요인이 설명력이 높다는 것으로 판단되었다.
각 요인에 구성된 항목을 보면 첫번째요인에 4개 항목 두번째 요인에 3개항목이 구성되어 있고
첫번째 요인은 만족도 두번째 요인은 친숙도로 명명하였다
요인 적재값은 모두 0.4이상으로 나타나 전반적인 측정 도구의 타당도를 만족하였으며,추가적인 항목제외 및 조정 없이 분석을 진행하였다.
두번째요인분석은 3개의 항목으로 요인분석을 하였다
KMO측도는 0.730 나타났고 누적분산이 76.526로 나타나 구성된 한개의 요인이 설명력이 높다는 것으로 판단되었다.
각 요인에 구성된 항목을 보면 첫번째 요인에 3개개 항목 되어 있고
첫번째 요인은 재구매의도로 명명하였다
요인 적재값은 모두 0.4이상으로 나타나 전반적인 측정 도구의 타당도를 만족하였으며,추가적인 항목제외 및 조정 없이 분석을 진행하였다.
두 번의 요인분석결과 구성된 요인들에 대한 신뢰도분석 결과를 각각 설명하시오
전반적만족도 재구매의도 친숙도의 내적 일관성 검증을 위해 신뢰도분석을 실시하였다.
주로 크론바흐 알파 계수를 산출하여 일반적으로 0.7이상이면 신뢰도가 양호한 것으로 판단한다.
전반적 만족도 재구매의도 친숙도에 대해서 각각 크론바흐 알파 계수를 산출한 결과, 모두 0.7이상으로 높게 나타나 본연구의 주요 벼수들의 신뢰도는 양호한 것으로 판단되었다. 따라서 신뢰도를 저해하는 문항은 없는 것으로 평가되었고, 문항 제거 없이 분석을 진행하였다.
'2.3 데이터분석 > SPSS 데이터 분석' 카테고리의 다른 글
| [데이터분석/SPSS] 독립표본 T- 검정 (2집단비교) (0) | 2023.05.17 |
|---|

댓글