웹 스크래핑(Web Scraping): 웹 페이지에서 특정 데이터를 추출하는 기술입니다. 페이지의 HTML 코드를 분석하여 원하는 텍스트, 이미지, 링크 등 다양한 정보를 추출한 후 저장하는 기술
자바로 웹 스크래핑하기 위해서 필요한 jsoup 라이브러리를 사용하보겠습니다.
Jsoup라이브러리는 자바로 만들어진 HTML parser로
DOM 구조를 추적하거나 CSS 선택자를 사용하여 데이터를 찾아 추출할 수 있습니다.
HTML의 구조와 데이터를 손쉽게 관리 할 수 있게 도와주는 라이브러리이다.
Jsoup 공식사이트
SpringBoot에서 사용해보기 (Gradle기준)
(일반 java프로젝트에서는 lib폴더에 Jar를 넣으면된다. https://jsoup.org/download )
1. build.gradle의 Dependencies에 아래 코드를 넣어줍니다.
implementation 'org.jsoup:jsoup:1.18.1'
1-1 Maven 기준
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.1</version>
</dependency>
간단하게 프로젝트 식으로 불러오는 방법을 실습해보겠습니다.
우선 불러오고자 하는 사이트의 robots.txt를 확인합니다.
저의 경우는 야후의 finance를 스크래핑하고자 합니다.
https://finance.yahoo.com/robots.txt
우선 제가 스크래핑하고자 하는 경로가 robots.txt에서 금지하고 있는지 확인하고
금지하고 있지 않을 경우 실행합니다
저같은경우는 finance.yahoo.com/quote에서 Coke의 1달주기의 테이블을 스크래핑을 하고자 합니다.
public static void main(String[] args) {
try{
Connection connection = Jsoup.connect("주소를 넣어주세요");
Document doc = connection.get();
Elements eles= doc.getElementsByAttributeValue("class","table yf-ewueuo noDl");
Element ele = eles.get(0);// table 전체
System.out.println(ele);
}catch(IOException e){
e.printStackTrace();
}
}위의 코드를 간단하게 설명을 하고 결과를 보여드리고 끝내도록 하겠습니다.
실습하기전 알아두면 Jsoup 사용 정보
Jsoup의 주요 클래스
Document 클래스
- 연결해서 얻어온 HTML 전체 문서
Element 클래스
- Document의 HTML 요소
- Element의 복수 클래스인 Elements가 따로 있다.
Jsoup 사용 문서 https://jsoup.org/apidocs/
Elements eles= doc.getElementsByAttributeValue("class","table yf-ewueuo noDl");
key의 value를 찾아서 반환해주는 메소드인데 여기서 key는 class value는 table yf-ewueuo noDl입니다
실제 웹사이트를 보면 class에서 제가 원하는 테이블이 가지고 있는 value였기에 이렇게 설정하였습니다
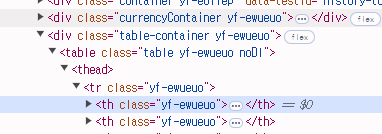
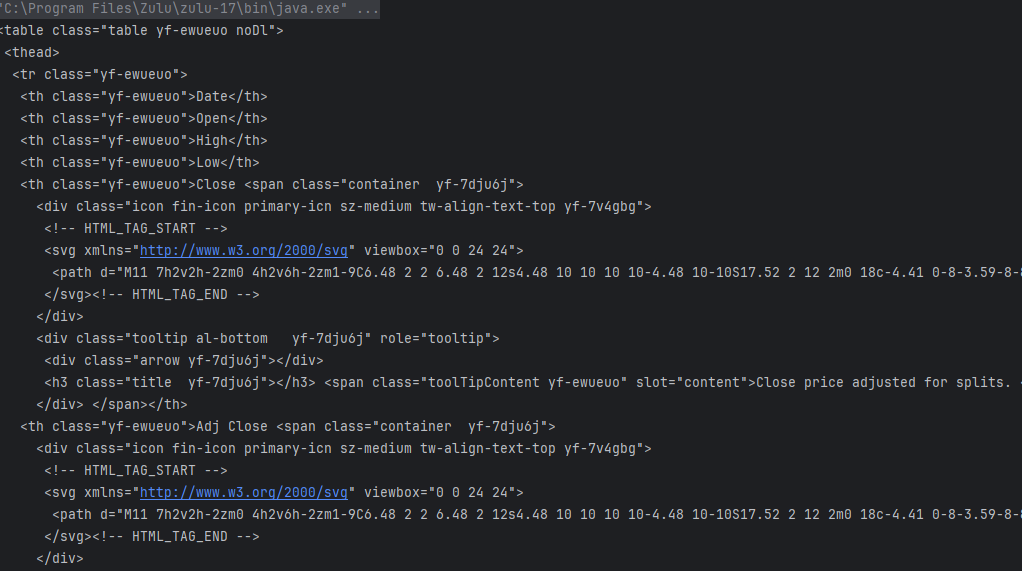
우선 해당 코드를 돌리게되면 아래 사진과 동일하게
값이 웹 스크래핑되어서 오는것을 알수있습니다.
자 이제 한번 원하는 방식으로 데이터를 변환하고 진짜 끝내봅시다.
우선 데이트를 봤을때 <thead> 다음에는 <tbody>가 나올 것입니다
<tbody>가 저희에겐 필요한 정보 이기 때문에 해당 데이터를 추출해보겠습니다.
public static void main(String[] args) {
try{
String URL = "주소";
Connection connection = Jsoup.connect(URL);
Document doc = connection.get();
Elements eles= doc.getElementsByAttributeValue("class","table yf-ewueuo noDl");
Element ele = eles.get(0);// table 전체
Element tbody = ele.children().get(1); // 하위 정보중 2번째 추출(Tbody)
for (Element tr : tbody.children()) {
String text = tr.text();
if(!text.endsWith("Dividend")){ //끝이 Dividend로 끝나지 않으면 버림
continue;
}
String[] split = text.split(" ");
String month = split[0];
int day = Integer.parseInt(split[1].replace(",",""));
int year = Integer.parseInt(split[2]);
String dividend = split[3];
System.out.println(year+"/"+month+"/"+day+" -> "+dividend);
}
}catch(IOException e){
e.printStackTrace();
}
}
자 해당코드를보면 ele는 테이블 전체였고
Element tbody = ele.children().get(1);로 테이블전체에서 tbody만 가져왔습니다.
그후 foreach문으로 각 row를 분리하였고 해당 row에서 Dividend로 끝난 경우에 데이터를 추출하는 방식입니다
해당 코드를 돌리면 다음과 같습니다.
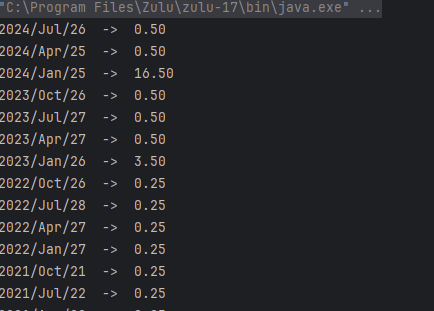
원하는 방식으로 데이터를 조작도 가능합니다 :)
이렇게 Jsoup에 대해서 간단하게 실습을 해봤는데요
읽어주셔서 감사합니다:)
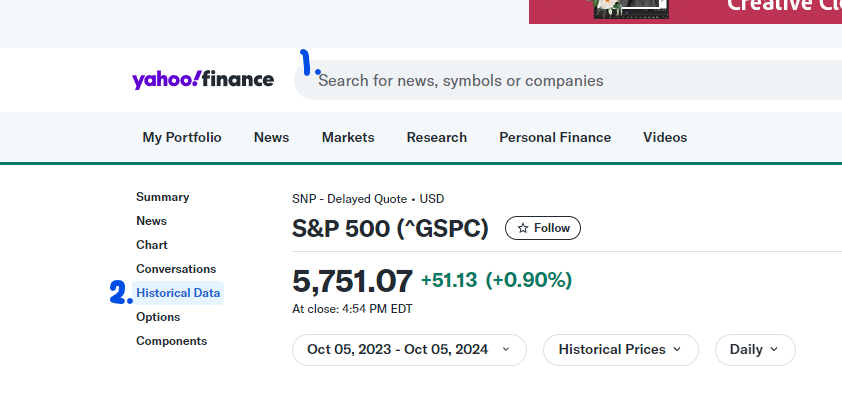
실제로 해보고 싶으신 분은 https://finance.yahoo.com/ 들어가셔서
제코드에서 1(검색창)에 주식을 검색하시고 2(Historical Data)번을 눌러서 해당 링크를 넣어보세요!
해당 코드는 완전하게 이 해당 웹사이트를 위해서 만들어 진 코드입니다
해당 코드를 다양한 웹사이트를 맞춰서 실습해보시면 좋을 것 같습니다:)
'3.1 Java_Backend > Java' 카테고리의 다른 글
| [Java] 스위치 표현식 Switch Expressions (0) | 2024.10.21 |
|---|---|
| [Java/구현] 집합 (0) | 2024.08.09 |
| [Java/기초] Stream (0) | 2024.08.05 |
| [Java/기초] 주석 (1) | 2024.07.22 |
| [Java/기초] 스트림 (0) | 2024.07.21 |
댓글